들어가면서
우리는 게임코치온라인(https://online.gamecoach.pro/) 서비스를 애자일 하게 개발하고 있다. 애자일의 가치와 효과를 경험하면서 목적지를 향해 (애자일 코치님의 팀 건강 검진 결과에 따르면🩺) 즐겁게 항해하고 있으며 K-애자일로 변질되지 않도록 부단히 노력하고 있다. 애자일은 함께 일하기 위한 관점으로써 우리가 무엇을-어떻게 만들어야 할지 안내하는 눈이 되어준다. 우리의 시야를 더욱 분명하게 개선하기 위한 노력 중 하나로 데이터 대시보드를 만들고 있으며, 현재까지의 과정을 공유한다.
애자일을 위한 데이터 대시보드?
스타트업은 모호함을 명확함으로 바꿔가는 과정이라고 생각한다.(by 모호좌👨💻) 우리는 끊임없이 무엇을 할 수 있는지, 언제까지 할 수 있는지에 대한 물음에 대답을 해야 하며, 결과물을 통해 어떤 성과를 얻을 수 있을지(또한 무엇을 얻었는지) 예측할 수 있어야 한다. 애자일 하다는 것은 어쩌면 이러한 질문들에 조금 더 정확한 대답을 찾기 위해 노력한다는 것일 수 있겠다. 하지만 완벽한 애자일 방법론이 완벽한 답변을 만들 수는 없다. 앞서 말했듯 애자일은 모호함을 선명하게 보기 위한 관점이기 때문이다. 우리는 선명한 시야를 가지고 서비스에 맞는 정답을 향해 나아가야만 정답에 가까워질 수 있다.
애자일을 위한 데이터는 우리 관점의 정확함을 검사할 수 있는 시력검사표 역할을 한다. 그것은 서비스가 현재 위치하는 곳을 제대로 파악하고, 우리가 예측했던 것이 얼마나 정확했는지 혹은 얼마나 틀렸는지를 바라볼 수 있는 검사 지표로써 동작할 것이다. 매번 돌아오는 스프린트의 성과를 측정하지 않으면서, 좋은 서비스로 나아가는 것을 기대한다면 복권 당첨을 기대하는 것과 다를 바 없다. 스케이트 보드의 바퀴가 제대로 굴러가지 않는 걸 모른 채 핸들을 추가한다면 그것은 킥보드로써 역할을 할 수 있을까?
애자일을 위한 여정에 동참하고, 지속적인 물음에 대답하기 위해 데이터 대시보드를 만들고 있다. 현재까지 구성한 대시보드는 다음과 같은 목표를 가지고 있다.
📌팀의 모든 구성원이 쉽게 확인할 수 있어야 한다.
📌데이터에 기반하여 아이디어를 구현할 수 있는 틀을 제공 해야 한다.
📌기능 추가/변경 시점을 기준으로 우리가 의도한 바를 달성하였는지 확인할 수 있어야 한다.
📌설계자의 질문에 대답할 수 있어야 한다. ex) 특정 기능 사용률, 수정한 기능에서의 구매 전환 변동률 등
기존 데이터 대시보드의 아쉬웠던 부분
레벨업지지 플랫폼을 개발하기 위해 Google 애널리틱스(이하 GA)와 아파치 제플린(디자인 툴 Zeplin 과는 다름)을 이용한 데이터 대시보드를 이용하고 있었다. 아파치 제플린을 이용하여 데이터베이스와 로그 저장소에 있는 데이터를 상세하게 조회할 수 있고 GA를 통해 웹에서 발생하는 이벤트들을 파악할 수 있지만 애자일 측면에서 몇 가지 아쉬운 부분이 있었다.
📌 대시보드로써 스토리가 부재하다.
🔸 데이터 대시보드는 표현하고자 하는 스토리가 분명해야 설득력 있게 데이터를 전달할 수 있다. 하지만 제플린으로 구성한 대시보드는 기능별(유저 사용성이 아닌)로만 대시보드가 분리되어있어 지표들 간의 상호관계가 없다.
🔸 아파치 제플린으로 구현된 데이터 대시보드는 근엄하고 위압감이 느껴진다. 개발자에게는 각종 테이블에서 뿜어내는 숫자들과 실시간으로 업데이트되는 데이터들이 다정하게 다가갈 수 있지만, 서비스를 운영하고 기획하는 분들에게는 대화를 거부하는 답정너 대시보드처럼 보일 수 있다.

📌유저와 서비스 간의 상호작용을 확인하기 어렵고, 특정 시점 기준으로 데이터를 비교하기 어렵다.
🔸 GA로 유저 이벤트를 수집하고 있었으나 이를 들여다볼 커스텀 보고서가 없었기에 이벤트 발생 빈도, 종류 등 단편적인 정보만 확인하고 있었다. 또한 커스텀 보고서를 이용하더라도 GA를 이용해서 확인할 수 있는 이벤트 상세 정보 (이벤트 벨류, 이벤트 로케이션 등)를 파악하기 어려운 문제점이 있다.
🔸 제플린으로 표현하는 차트들은 기간을 기준으로 비교하기 어렵다. (GA에서는 최근 2주에 대한 데이터를 조회하면 자동으로 과거 4~3주 차의 데이터와 비교해서 지표 증감률을 표현해준다.)
새롭게 추가된 데이터 대시보드
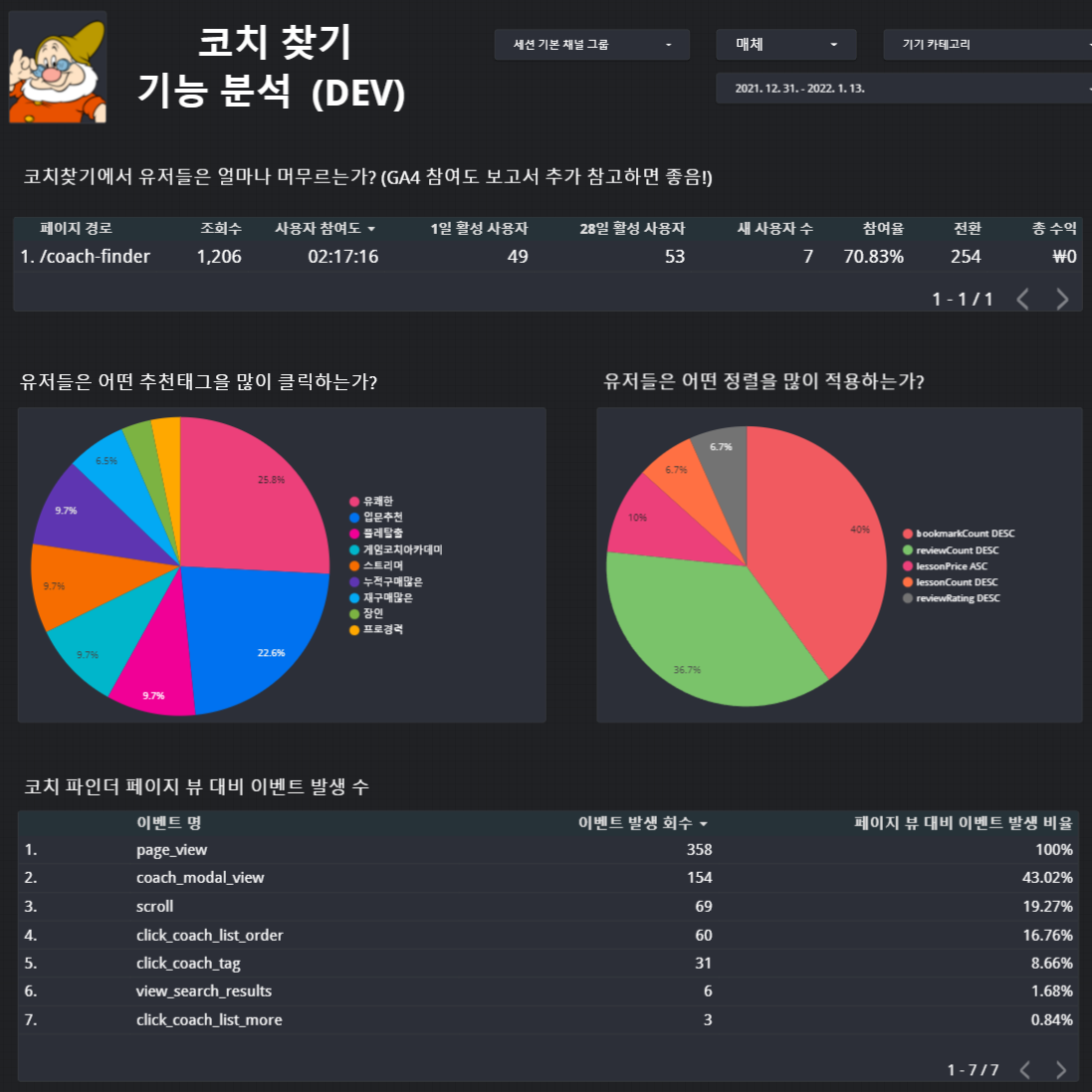
게임코치 온라인 서비스를 개발하는 팀원 전체가 이해하기 쉽고 친근하게 다가갈 수 있는 대시보드 형태가 무엇일까 고민하다 AARRR 해적 지표를 구글 데이터 스튜디오로 구현하는 것을 목표로 첫 번째 대시보드를 만들었다. 우리 서비스의 현재 상황을 파악할 수 있고 개선해야 할 포인트를 드러내서 새로운 아이디어를 유도할 수 있는 지표라고 생각했기 때문이다. 두 번째로 특정 기능에 집중하지 않고, 유저 스토리를 기준으로 데이터를 표현하는 대시보드를 추가했다. 예를 들면 '코치 찾기 스토리' 대시보드의 경우 '유저들은 어떤 추천 태그를 많이 클릭하는가?', '유저들은 어떤 정렬을 많이 적용하는가?', '유저들은 코치 찾기 페이지를 얼마나 탐색하는가?'에 대한 기획자의 질문에 대답할 수 있는 데이터를 중심으로 시각화해서 데이터 가독성을 높이는데 집중한 것이다.
📌AARRR FUNNEL 대시보드
🔸 서비스를 이용하는 유저의 획득부터 수익, 레퍼럴까지 FUNNEL(깔때기) 형태로 데이터를 표현하여 위에서부터 아래로 데이터를 읽어 갈 수 있도록 구성했다. 데이터를 읽어가는 방향을 제공한다는 점에서, 기존에 사용 중인 GA 보고서와 제플린의 차트와 가장 대비되는 부분이다.
🔸 대시보드 구성을 위한 데이터 소스로 GA4(새로운 버전의 GA로 빅쿼리를 무료버전에서도 사용할 수 있다.)와 GA3(GA4 이전 버전인 UA 버전), Google BigQuery를 모두 사용하여 GA에 친숙하지 않은 사용자도 배포일 기준으로 방문자나 전환(수익)이 얼마나 발생했는지 쉽게 확인할 수 있다.
🔸 AARRR 대시보드를 통해서 우리가 집중해야 하는 부분을 파악할 수 있고 "새로운 기능 A는 무엇을 개선하기 위함인가?", "이번에 배포된 기능 B는 우리가 개선하고자 했던 목표를 달성했는가?" 등 팀원들의 질문에 대답할 수 있다. 그리고 데이터에 기반하여 지나간 스프린트를 회고하고 우리가 했던 예측과 대답들이 얼마나 정확했는지 판단할 수 있기 때문에 우리 대답의 정답률을 높이는데 도움이 될 것이다.
📌코치 찾기 페이지 대시보드
🔸 스프린트 리뷰&회고 시간을 통해 AARRR대시보드를 팀에 공유 한 뒤, 서비스 전체 관점이 아닌 에픽이나 유저 스토리 기준의 대시보드의 필요성에 대해서 대화를 나누었다.
우리는 에픽이나 스토리의 성과를 측정할 수 있는 지표를 데이터 기반으로 설정하여 무엇이 목표인지 분명히 하고자 했다. 또한 유저 스토리 적용 전부터 부재되어있던 데이터를 미리 쌓아 기능 배포 이전과 이후를 비교할 수 있는 환경을 구축하고자 했다. (스토리 적용 전/후 비교를 통해 에픽의 성공 여부와 개선점을 다시 찾을 수 있기 때문에)
그래서 에픽을 작성하는 단계에서부터 에픽의 목적과 효과를 데이터에 기반하여 설정하였고, 유저에게 개발 내용이 전달되었을 때 변화를 측정할 수 있도록 데이터 수집 요청 일감을 스토리 개발과 같은 스프린트에 추가하여 데이터 대시보드 구성을 하나의 업무로서 진행하게 되었다.
🔸 에픽이나 유저 스토리 기반의 데이터 대시보드는 유저의 클릭, 스크롤 상황 등 DB에 저장하지 않는 단순한 유저 상호작용을 모아 메인 데이터로 사용한다.
그렇기 때문에 GA4, GA3(UA버전)을 데이터 소스로 만들었던 AARRR대시보드와는 달리 GA4로 수집하고 있는 유저 이벤트를 좀 더 상세히 분석해야만 했고 GA4를 연동한 구글 BigQuery를 데이터 소스로 추가하였다. GA4 <-> BigQuery를 이용하면 이벤트의 상세 내용까지 추출할 수 있고, 데이터 요청자의 질문에 더 상세하게 대답할 수 있게 때문에 데이터 대시보드를 구축하는데 큰 도움이 되었다.
앞으로 개선이 필요한 부분
애자일을 위한 데이터 대시보드를 공개하고, 다양한 의견들이 더해지면서 개선이 필요한 부분들을 찾을 수 있었다. 수강 유저와 코칭 유저로 고객군을 분리하는 것, GA 유저 획득 소스가 not set과 direct 부분을 분석하는 것 등 공감되는 부분이 많았다. 의견들을 반영하여 대시보드를 개선하기 위해 다음과 같은 작업을 진행할 계획이다.
📌GA 수집 데이터 상세화
🔸 고객군 분리: 게임코치 온라인은 코치님과 수강생을 연결하는 서비스를 제공하기 때문에, 고객군을 수강 유저와 코칭 유저로 나눌 수 있다. 두 개의 고객군에게 제공하는 서비스와 집중해야 할 데이터가 다르기 때문에 대시보드도 분리하여 볼 수 있는 기능이 필요하다.
🔸 유저 획득 들여다보기: GA특성상 많은 유저 획득이 not set이나, direct로 집계된다. AARRR대시보드의 분석 첫 단계로 획득 단계가 구체화될수록 기초를 단단하게 할 수 있을 것이다. 유저 획득을 상세화하고 구분하는 것은 GA를 사용하는 많은 팀들이 같이 고민하는 이슈로 UTM, 뷰저블 등 다양한 방법을 이용하여 not set과 direct를 줄여보려 한다.
📌대시보드 데이터 리소스 추가 & 연결(Join)
🔸 코칭 서비스의 친구 초대 이벤트를 상세 추적하거나, 프로모션에 투입된 비용 대비 유적 획득 비용을 계산하는 대시보드를 작업하기 위해서는 GA와 서비스 DB, 광고 비용 정보 등 다양한 데이터 리소스를 연결(Join) 해서 보아야 한다. 예를 들어 GA에서 추적한 데이터와 코칭 서비스 DB를 연결하여 대시보드를 구성한다면 구매 유저의 수강 횟수나, 잔여 포인트 현황 등을 함께 볼 수 있어 좀 더 리더블한 대시보드를 만들 수 있을 것이다.
마무리
우리는 더 좋은 서비스를 만들기 위해 애자일 하게 일하고 있다. 지속적으로 쌓아온 데이터를 분석하여 예측을 하고 유저와 상호작용을 분석하여 예측 결과를 평가한다. 그리고 더 나은 예측을 기대한다. 좋은 서비스를 만드는 것은 서비스를 만드는 사람들의 공통적인 목표일 것이다. (애자일 방법론을 떠나서라도) 팀에서 활용하고 있는 데이터에 스토리를 더하고 더 나은 예측을 위한 노력은 좋은 서비스를 만드는데 도움이 될 것이라 믿는다. 계속해서 발전시켜나갈 데이터 대시보드가 더 좋은 제품을 위한 우리 팀의 노력에 보탬이 될 수 있으면 좋겠다.

김병규 (bk@bigpi.co)
새로움과 자유로움을 좋아하는 개발자입니다.
프로덕트의 성장은 구성원의 성장으로부터 온다고 믿습니다.
'DATA' 카테고리의 다른 글
| [애자일로 빅픽처를 그리다] 데이터 대시보드 #2 (1405) | 2022.03.11 |
|---|---|
| JDBC에서 Batch Processing 이란? (Mybatis 연동) (0) | 2016.06.21 |
| Flyway 개념 & 사용법 (519) | 2015.11.05 |


